Author: Elizabeth

IAP2 NAC: Digital Engagement Strategies for a Divided Room
Over 150 people tuned in last month for our IAP2 NAC Technology Panel session: Digital Engagement Strategies for a Divided Room.

Building Meaningful Digital Engagement with Community: Design and Content Planning
This post is part of a series in which we’ll help you plan, build, promote and manage your online community engagement initiatives. In this post, we’ll explore the design and content planning phases of digital public engagement as well as key considerations for achieving meaningful engagement with community members. We also recommend reading through the first post in this series in which we covered the process of setting goals and reporting objectives for online public engagement initiatives.
In our last post, we discussed how the COVID-19 pandemic reshaped public engagement. As engagement practitioners, the pandemic demanded that we quickly innovate, test and adopt new solutions for all aspects of civic engagement that were no longer possible due to constraints on in-person gatherings; for example, meetings formerly held in community centres moved to virtual town halls and discussions that once took place in-person moved to moderated online forums.
While it appears that we are now at the tail-end of the COVID-19 pandemic as restrictions on gathering have been lifted in most public settings, the advantages gleaned from digital innovation during the pandemic remain. Many organizations are opting to keep their public engagement online to continue reaping the benefits of cost-savings, accessibility, capacity-building, transparency, community ownership and relationship infrastructure that digital public engagement affords. Those that are choosing to return to some level of in-person engagement with community members are considering hybrid strategies that employ both digital and in-person mediums. Thus, even post-pandemic, digital public engagement remains a critical tool in the public engagement toolkit.
In this post, we’ll guide you through several important decision points that you’ll encounter during the design and content planning phases of your next digital public engagement initiative.
Designing the engagement and planning the content
When consulting participants on a particular topic, it can be tempting to duplicate the structure established in a paper or deck that your organization has already prepared on the subject. Instead, identify what the different pieces of content related to the engagement experience will be and consider how you want participants to move between them. Think about how participants interact with the concepts you are engaging them on in the real world. This will likely differ from the highly linear format of publications that are pieces of one-way communication.
The following guidelines come from the field of user experience design. The practice is used extensively in website design and interaction design, and it is intended to help plan experiences that are elegant, intuitive and friendly.
Identifying participants
To create a thoughtful and inclusive engagement experience, it is critical to identify who your participants will be. The characteristics of your participant groups will inform your engagement initiative’s design by directing language requirements, accessibility needs, demands of user effort and other dimensions critical to participation. If you have the resources, identifying your participant personas (characters that represent the different target audiences of the consultation) and stories (goals and motivations) is an excellent practice.
It is important to identify and analyze the full spectrum of your engagement initiative’s targeted participants, paying special attention to underrepresented participant groups who may require additional support to ensure meaningful engagement. The Government of Newfoundland and Labrador’s Public Engagement Guide offers some excellent strategies for accomplishing inclusive engagement with community. The Guide also offers a matrix for mapping consultation stakeholders, which is a useful exercise not only in that it allows designers to identify participant groups but also in that it will yield information about stakeholders’ positions and knowledge levels (The Government of Newfoundland and Labrador, pg 17).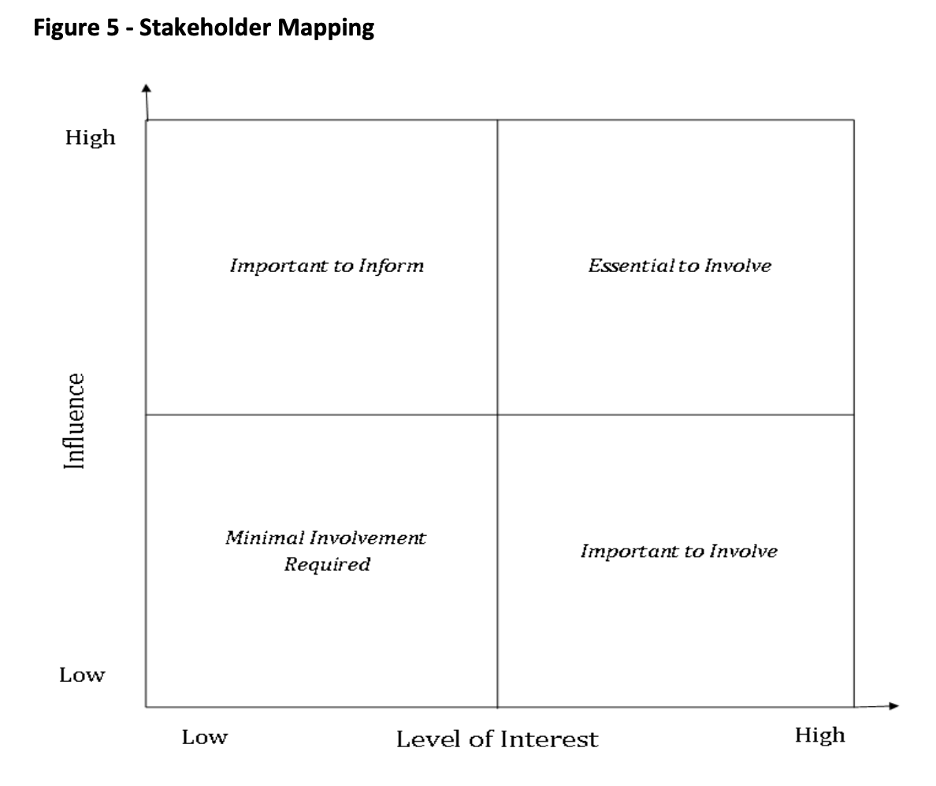
The Government of Newfoundland and Labrador, The Government of Newfoundland and Labrador’s Public Engagement Guide, pg. 17, retrieved from: https://www.gov.nl.ca/pep/files/Public-Engagement-Guide.pdf
Logical grouping of content and activities
Meaningful participation opportunities guide participants to make choices that are informed. As the engagement architect, it is your responsibility to ensure that relevant information and other content are presented to the participant in a logical fashion. Identify what information participants require to make informed choices and identify themes or categories that can be used to organize the different activities. Providing a set of categories can help participants set a mental model that reflects the way they think about the topics in the real world. Organizing information and activities into content groupings will allow you to begin building your engagement initiative’s information architecture. Doing this will not only allow you to ensure that you are not missing any required pieces of context, but also that the right pieces of context are presented to the participant in the right spots. Where possible, it is best to present the participant with the information that is relevant to a particular participation opportunity immediately preceding that opportunity. For example, if your digital engagement with community members asks them about their experiences with the five most commonly sighted birds in North America, it is best to list and describe those five birds immediately preceding the question and input mechanism.
Break it down
Tip: If you are using a discussion paper, break it down into several discussion topics. Present these topics as self-contained spaces or activities and present input prompts in context. Participants will be more likely to provide input if they are not forced to read through a long document, and if they have an easy way to find the topics that are relevant to them.
Linear vs. non-linear structuring
Linear structuring
Your design should help participants move from one activity to another. If the order in which engagement activities are completed matters, then you will need to employ a linear structure that guides participants along a fixed path. This is often the case with surveys that employ screening questions. For example, imagine that you are consulting participants on the climate change mitigation strategies that they would be willing to implement in their neighbourhoods and the list of potential strategies shown to the participant will change depending on what postal code information the participant provides. Since responses to the postal code question will determine the set of strategies shown in the climate change strategies section, this consultation would need to be structured in a linear fashion. Participants would need to be provided with the questions on demographics prior to being provided with the questions on climate change strategies. When constructing linear surveys, consider using pagination to decrease the perceived effort of completing the survey.
Non-linear structuring
More often when conducting digital engagement with community members, you won’t need your participants to complete consultation activities in a particular order. When this is the case, it is best to use a non-linear structure to organize your engagement initiative. Applying a non-linear structure allows participants to complete activities in their preferred order and this often results in higher participation rates because it enables participants to engage on topics that are most important to them first. In a linear consultation, participants may not be shown the topics that they’re interested in until they have completed other activities first; unless a participant is highly motivated to participate, they may lose interest and drop-off, resulting in lower completion rates. When designing a non-linear experience, provide participants with a navigation system that gives users direct access to different activities. It is helpful to offer a completion tracking mechanism (such as 76engage’s activity tracking feature) for participants to see which activities they have completed, and which are pending. Completion tracking can also be used to encourage participants to complete all activities.
When possible, we recommend taking the time to prepare a user flow diagram. This will provide your team with an opportunity to consider your engagement initiative’s requirements for linear vs. non-linear structuring as well as provide a visualization of participants’ journey through the engagement experience.
All at once or phased?
If you need participants to follow a specific flow and if you are consulting over a few weeks or months, consider phasing the publishing of topics. Presenting a few topics at a time can help focus participation and optimize your consultation’s engagement with community members.
Think beyond surveys
Questionnaires are often the first (and in many cases, only) activity that engagement managers consider when planning a digital consultation. However, if you are using a digital engagement platform, then you likely have a range of different activities (such as discussion forums, interactive maps and virtual open houses) available to you that may be better suited to the initiative. Learn about your platform and make use of the features that the digital medium offers. For example, when gathering input about places, such as construction sites, landmarks, or train stations, use interactive maps to give participants a visual way to associate the activities with the places that matter to them most. Additionally, organizations that use a hybrid of in-person and digital mediums to structure their engagement with community members often use interactive maps to plan and display the locations of in-person meetings.
Next up…
Now you have a solid plan: you have identified the objectives, thought through the reporting metrics, and you have chosen the right engagement tools. It is now time to choose the engagement tools and program the activities.
For more information on our state-of-the-art digital engagement platform, visit 76engage.com. Our next blog post looks at choosing the right engagement tools. Stay tuned.

76engage is the Technology Lead Sponsor at the IAP2 North American Conference this year #IAP2NAC
We’re excited to be the Technology Lead Sponsor at this year’s North American Conference in Banff for the International Association of Public Participation. Our CEO, Joseph Thornley, will be presenting a session on Thursday on choice architecture and its impact on online engagement experiences. Be sure to drop by our exhibition booth and let’s discuss how digital engagement can fit into your organization’s engagement strategy.
See you there! #IAP2NAC


Public engagement in the “Post-Covid” world: Step One – Planning
Public Engagement in the Post-Covid World
For over two years, the COVID-19 pandemic affected almost every aspect of our personal and professional lives. For public/stakeholder engagement professionals, the practice of public engagement may have changed forever.
Prior to the COVID-19 pandemic, geographic, mobility and other ability constraints were already preventing groups of stakeholders from being able to access open houses, town hall meetings and other venues of in-person public engagement. Today, of the citizens who were able to attend in-person public engagement opportunities prior to the COVID-19 pandemic, it seems unlikely that all will feel comfortable gathering in crowded community centres or hotel function rooms in the shadow of the pandemic – particularly for citizens that have health risk factors or live with those that do. Moreover, years of global pandemic living have shifted our behaviours, schedules and physical locations. Physical gathering places in urban areas that may have been easily accessible to those working in corporate office buildings are unlikely to be as accessible for those same individuals who are now permanently working from home.
Accordingly, digital public engagement is a crucial tool in the post-COVID public engagement toolkit that will ensure that a planned consultation will reach all targeted groups of stakeholders. Online public engagement offers the benefits of being highly cost-effective and widely accessible while still offering stakeholders and citizens real opportunities to provide meaningful input. If configured properly, digital engagements can be every bit as flexible, comprehensive and robust as in-person engagements, while significantly increasing reach and the number of participants. But care must be taken in designing, managing, and reporting on digital engagements if their full potential is to be realized.
In this blog series we’ll help you plan, build, promote and manage digital engagements. Digital engagements require the use of digital platforms, such as 76engage, through which organizations can connect with participants, listen to their goals, gather their input and collaborate on solutions. In this first of our planning blog posts, we cover the process of setting goals and reporting objectives.
Planning Part 1: Setting goals and reporting objectives
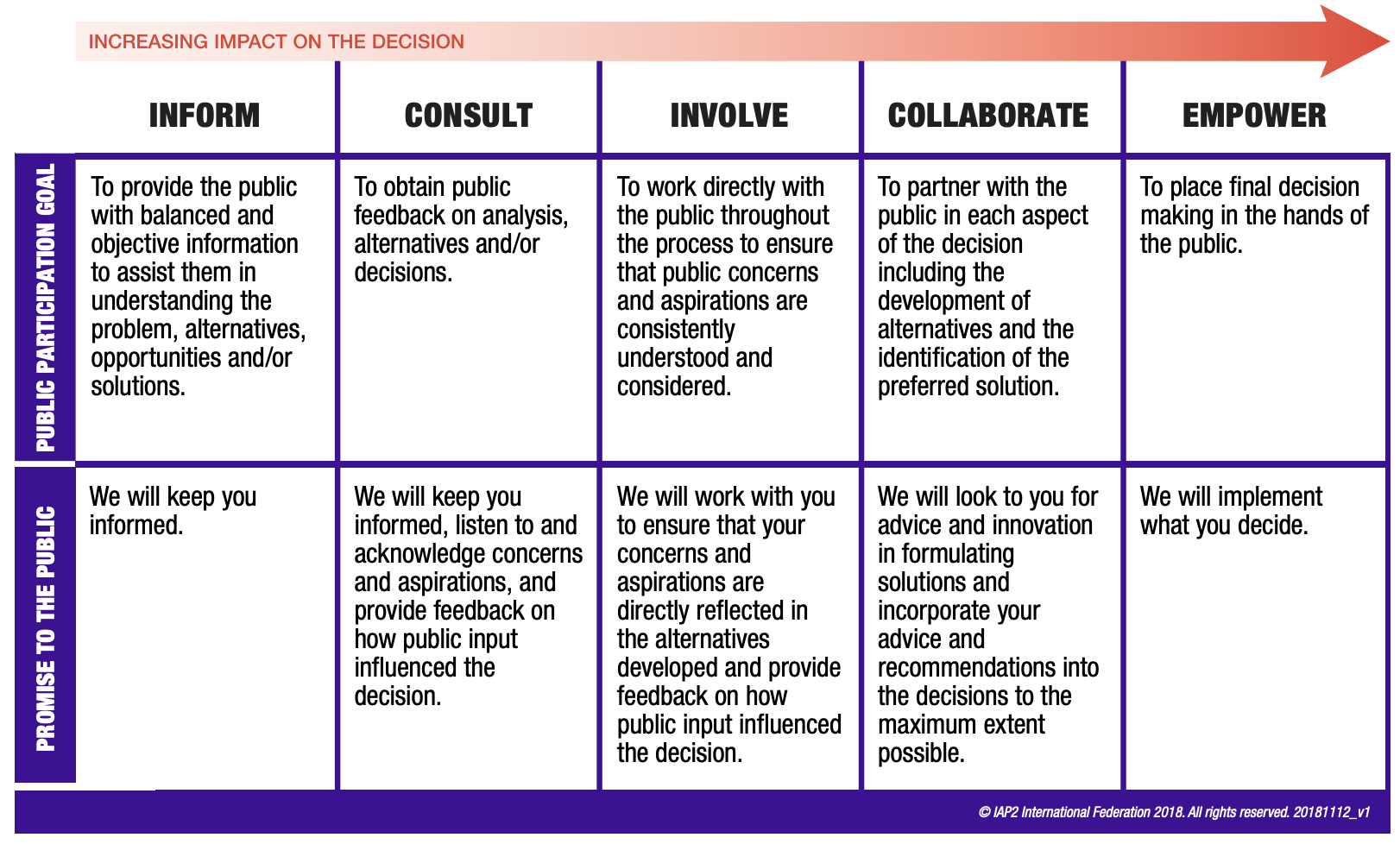
The first step to conducting any public engagement is to establish the goal of the consultation. The IAP2 Spectrum of Participation published by the International Association of Public Participation (IAP2) provides a handy chart to help you situate your engagement goal and understand the corresponding promise to the public. Knowing the goal and the promise will help you frame the engagement and choose the right tools. Many organizations that primarily used in-person public engagement tools (ex. open houses, town halls, door-knocking) prior to the pandemic switched to digital public engagement tools (ex. virtual town halls and online questionnaires, forums, and polls) during pandemic. These organizations are now grappling with the decision of where to go next: should they return to conducting solely in-person public engagement, continue conducting solely virtual public engagement or develop a hybrid strategy?
In-person, virtual or hybrid?
The decision of whether continued engagement is done solely online or in combination with in-person engagement should depend on who the target participants are for this particular consultation. For example, if your organization needs to obtain input from audiences with limited access to the internet (such as those living in rural or underserved areas), it is important that you also use in-person consultation tools. While COVID-19 made this nearly impossible for the past several years, we are now beginning to foresee a day when open houses and town hall meetings will return to the consultation landscape. If you are planning a consultation for a set of stakeholders that you’ve consulted with recently, now is a great time to take the temperature. Ask them how they would prefer to be consulted with (in-person, online or a mix of both) so that you can co-create this aspect of your organization’s engagement strategy.
Many organizations who experienced the pain points of switching from a purely in-person consultation strategy to a digital consultation strategy at the start of the pandemic are recognizing the risks of not maintaining some level of digital public engagement moving forward. While we hope to never experience a global crisis of the COVID-19 pandemic’s scale again in our lifetime, there are no certainties that another health or climate crisis will not drive the world to a halt again. Having an online public engagement strategy already established and digital infrastructure regularly being used as a tool in your organization’s engagement toolkit will make it much easier to rely on when needed.
One-off or ongoing?
Consider and define whether this a one-off engagement or the start of an ongoing relationship with your audience. For engagements that are intended to be part of an ongoing relationship, consider using an online public engagement platform. Online public engagement platforms (also known as “digital public engagement platforms”, “community engagement platforms”, “audience engagement platforms”) combine a collection of engagement tools under one roof. Online engagement platforms are ideal for ongoing engagements because they allow participants to join a digital space where they can build relationships with organizations over time.
As governments move towards more openness with open dialogue at the core of a citizen-centric government style, sustained and ongoing engagement will become the common ground where government and citizens will come together to discuss and make decisions. A key benefit of online engagement platforms is that they allow participants to track their engagement history overtime, see a record of their individual engagement and track topics that are important to them, creating a greater sense of participant ownership in the process. Additionally, online engagement platforms allow participants to maintain and update account profiles. These profiles contain information about their interests, allowing organizations to invite participants from past engagements to participate in new initiatives. These profiles can also contain demographic information, removing the need to ask for it over and over each time you run a new engagement.
What about privacy and data ownership?
With good reason, there is increased wariness about the state of online privacy. The COVID-19 pandemic required many workplaces to shift to remote work and many industries to move their services online, leading to a marked increase in the volume of data breaches and leaks of personally-identifiable information. A recent study by KPMG found that 68% of respondents were concerned about the level of data being collected by organizations and 40% don’t trust companies to use their data ethically.
The success of your consultations depends largely on the trust that participants have in the process. As the organization running the consultation, it is paramount that you ensure that participant data, particularly their personal information, is kept private and safe at all times. Make sure that the data is housed on secure databases located in the country where participants live.
In terms of data ownership, make sure that the company that provides you with the technology makes it clear that:
- you own all of the data;
- this data can be moved from the platform to other tools;
- they will never use any of the data for any purpose;
- they will delete and destroy all of the data following the termination of the contract.
Defining reporting objectives
When planning an online public engagement, think about how you will need to report the outcome of the engagement upfront. Having a clear idea about your reporting needs will ensure that you are asking the right questions from the start.
Knowing how you will want to break down the input, for example, across different demographic indicators, will help you determine which pieces of information you will need to collect from participants.
Tip: When we consult on online public engagement projects, we often see clients build out drafts of multi-page surveys with demographic questions placed at the very beginning of the survey. This often leads to higher drop-off rates. Unless used for screening, we recommend placing demographic at the end of a survey and instead, beginning the survey with questions about the topic that enticed the participant to click the link to take the survey. For example, if your organization has asked potential participants to take a survey about their recent experience with city parks in order to inform the design of new parks being built, consider starting the survey with a question like “What features are currently missing in your local park that you would like to see in a new park in the city?” rather than demographic questions.
As you identify your reporting objectives, you will be able to compile a list of what data points you require from participants. Once this list of data points has been identified, try not to ask for more information. Asking for the minimum amount of information possible will reduce participation barriers and increase the likelihood that participants hit the ‘submit’ button.
For more information on our state-of-the-art digital engagement platform, visit 76engage. Our next blog post digs into designing your engagement and preparing the content. Stay tuned.
Big claims are made about the future of artificial intelligence and machine learning – but your datasets are small. What does this mean for you?
In 2021, 76% of sampled enterprises have prioritized artificial intelligence (AI) and machine learning (ML) over other IT initiatives, according to a study by Algorithmia (Columbus, 2021). Despite increased spending on artificial intelligence and machine learning projects across industries, many organizations with small datasets are left wondering how they can leverage their existing datasets to implement these solutions.
For the purpose of analytics and prediction, machine learning solutions require high-quality, large datasets that can be used to train algorithmic models. Here, ‘high-quality’ and ‘large’ refer to data that is essential, diverse and representative for your project and that has undergone adequate feature transformation (formatting, cleaning, feature extraction). When we consider the size of a dataset needed to train a relatively simple model, Telus International discusses the ‘Rule of 10’:
“One common and much debated rule of thumb is that a model will often need ten times more data than it has degrees of freedom. A degree of freedom can be a parameter which affects the model’s output, an attribute of one of your data points or, more simply, a column in your dataset. The rule of 10 aims to compensate for the variability that those combined parameters bring to the model’s input.” (Telus International, 2021)
With datasets that are large enough, the effects of both bias and variance are minimized in models, empowering very different machine learning algorithms to perform virtually the same. This is a key driver for why companies like Google, Facebook, Amazon, and Twitter, are dominant in artificial intelligence research.
But what if your organization isn’t a tech giant with access to minute data from a user base of millions? What if your datasets are “small”? In this case, do machine learning and artificial intelligence solutions still have a role to play in your analytics strategy? The answer is yes, but with a little help. The following are some techniques that can be used to evade the small data challenge.
- Synthetic data generation: synthetic data tools are used to generate synthetic data to match the collected ‘real-world’ sample data, while ensuring that the sample data’s important statistical properties are reflected in the synthetic data. According to Gartner, 60% of the data used for the development of artificial intelligence and analytics projects will be synthetically generated by 2024 (White, 2021).
- Low-shot learning/Few-shot learning: low-shot/few-shot learning is a technique that enables a model to make a prediction based on a small number of training examples. In practice, a machine learning model may be given thousands of simple inspection tasks, each of which only has a small number of training examples. This enables the model to spot the most critical patterns since it only has a small dataset to draw from.
- Transfer learning: transfer learning is a technique that allows small datasets to be supplemented by storing knowledge gained while solving a related (but different) problem that ample data is available for. This knowledge is then applied to the small dataset model or problem. For example, knowledge gained while learning to identify trees could apply when seeking to identify shrubs.

Columbus, Louis. 76% Of Enterprises Prioritize AI & Machine Learning In 2021 IT Budgets. (2021). Retrieved from https://www.forbes.com/sites/louiscolumbus/2021/01/17/76-of-enterprises-prioritize-ai–machine-learning-in-2021-it-budgets/?sh=53ca5af2618a
Telus International. How much AI training data do you need?. (2021). Retrieved from https://www.telusinternational.com/articles/how-much-ai-training-data-do-you-need
White, Andrew. By 2024, 60% of the data used for the development of AI and analytics projects will be synthetically generated. (2021). Retrieved from https://blogs.gartner.com/andrew_white/2021/07/24/by-2024-60-of-the-data-used-for-the-development-of-ai-and-analytics-projects-will-be-synthetically-generated/
Recent Comments